Today I joined IBM’s Machine Learning Everywhere: Build Your Ladder to AI webinar to hear about some of the latest trends in adopting Machine Learning into an organization, and of course plugs for several of IBM’s products in that space.
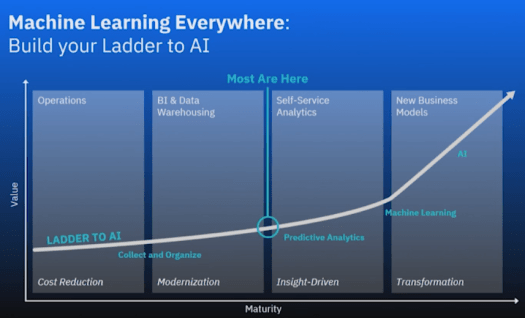
Rob Thomas is General Manager of Analytics at IBM. His main topic was that there is a ladder that must be climbed for the effective use of Machine Learning and Artificial Intelligence. Per Rob, the technology has finally caught up and “2018 is the year to implement Machine Learning.” Part of that is instilling a data-driven culture.
The first rung is that AI is not possible if your data is not simplified and collected into a data lake. Traditional business analytics with a solid data strategy is essentially the prerequisite for a shift into ML. As part of this, the point was made that AI is perceived is being only for hyper-scaling big players like Uber, Airbnb and Facebook but that recent advancements really make it available to all. An insight that really resonated with me was that 80% of the world’s data is sitting unused and neglected behind corporate firewalls.
The second rung is that data must be accessible. Policy and governance must be in place so that data is at the fingertips of the users that need it most. Of course, there are complications with financial data and HIPPA protected data. The idea is to install the data driven culture by making as much data available to anyone who needs it in a self-service manner.
The top rung is built upon traditional analytics and business intelligence—the actual utilization of Machine Learning in every decision. Once data is widely accessible, decisions based on hunches become less viable and people learn to interact with their data using ever more sophisticated tools. This is the destination of all successful companies in the future: data driven decision making.
Rob mentioned the 40/40/20 rule about companies adopting a data driven culture:
- Stage 1: 40% are data aware and are building out incremental efficiencies in their data processing, using both proprietary and open-source tools to create their data lakes. Data collection and data cleansing are the current investments.
- Stage 2: 40% are actively examining their data looking for new ways to grow. Regardless of their actual industry, they are becoming a technology company.
- Stage 3: 20% are exploring Machine Learning with the intention of being data led. It’s the end of opinions. They are evolving to use ML to automate tasks they never wanted to do in the first place.
Vitaly Tsivin of AMC Networks and Alissa Hess of USAA both shared examples of how Machine Learning and data science are being used to transform their companies from the inside out. However, both noted that the biggest barrier to success is finding talent. The combination of understanding data, understanding technology, and understanding business is rare in a person and difficult to hire.
The webinar ended with a presentation by Garry Kasparov, the first chess grand master to be defeated by a computer, and his opinions on the limitations and direction of artificial intelligence.
The first hour is well worth the time.






